ドメイン評価のDAとPA、DRとURはどうやって計算しているのか?

Mozが算出している評価指標のDAとPA、ahrefsが算出している評価指標のDRとPR、それぞれどのような違いがあり、どのように決まるのでしょうか?
具体的な計算方法は明かされていませんが、いずれも相対評価で計算していることがわかっています。
この記事では、DAとPA、DRとUR、それぞれの違いや、わかっている計算要素について解説します。
共通していること
- 計算アルゴリズムは非公開。たびたびアップデートされている。
- 主にリンクの量と質を見ている。
- それ以外にも、検索結果やFollowの有無など、様々な要素が絡んでいる。
- 最高点数は100
- データを取得した全ドメインの「相対評価」で算出しているので、放置サイトでも上下することがある。
- 対数目盛りでランク分けしているので、低ランクから中ランクは簡単。中ランクから高ランクは難しい。
- Q.「どうやったら上がる?」A.「被リンク」
DR(Domain Rating)とは
DR(Domain Rating)とは、ahrefs社が独自で算出しているドメインの評価指標です。
参考:What is Domain Rating (DR)?
計算アルゴリズムは非公開ですが、上記記事から以下のことが判明しています。
- 被リンクのリンクの量と質を見ている
- リンクジュースを考慮している
- 把握している全ドメインの相対評価で順位付けしている
UR(URL Rating)とは
UR(URL Rating)とは、ahrefs社が独自で算出しているページの評価指標です。
参考:What is URL Rating (UR)?
DRがドメイン単位の評価指標なのに対し、URはページ(URL)単位の評価になります。
こちらもDR同様計算アルゴリズムは非公開ですが、上記記事から以下のことが判明しています。
- 対数スケールで算出されている。
- 内部リンクと外部リンクの両方が計算要因になっている。
- follow nofollowも考慮されている
- スパムリンクは独自アルゴリズムではじいている
- 「リンクループ」(2つのウェブサイト間で何度も重複して評価されること)を避けるアルゴリズムがある。
DA(Domain Authority)とは
DA(Domain Authority)とは、Moz社が独自に算出しているドメイン評価指標です。
参考:What is Domain Authority and why is it important?
こちらもahrefsのDR,URと同じく計算アルゴリズムは非公開ですが、紹介記事から以下のことが判明しています。
- 計算には、機械学習モデルを使用している
- 計算には合計40以上の要素が使用されている
- 使用が確定しているデータ:検索結果のランキング、リンク元ドメイン、リンクの総数
- 計算アルゴリズムはアップデートを繰り返しており、直近では2019年に実施された
- 相対評価である
- 常にドメイン・オーソリティのスコアが1から始まる
PA(Page Authority)とは
PAとは(Page Authority)とは、Moz社が独自に算出しているページ(URL)評価指標です。
参考:What is Page Authority?
こちらも上記記事から以下のことが判明しています。
- 100ポイントの対数スケールで採点されている。
- ページオーソリティとドメインオーソリティの計算方法は同じ
相対評価とは?DRとDAの計算方法の予測
あくまで予想の範疇なのですが、ahrefsのDRもMozのDAも、以下のような計算方法なのではないかと思います。
以降、計算式が出てきますが、あくまでイメージですので「信憑性は全くない」という前提で読み進めてください。
ステップ1.係数を決めてドメインごとの点数を出す
![]()
ドメインのスコア=
a(補正係数)×{リンク1の質+リンク2の質+・・・・+リンクNの質}
※リンク本数分足し上げ
+
b(補正係数)×{キーワード1の難易度×キーワード1のトラフィック量+キーワード2の難易度×キーワード2のトラフィック量+・・・+キーワードMの難易度×キーワードMのトラフィック量}
リンクの質と本数を元にスコアを決定しているなら、それぞれのリンクの質と本数を足し上げたものがスコアになると仮定するのが妥当です。
リンクの質には、follow/nofollowも考慮されていると思います。
また、トラフィック量も少なからず影響を与えていると考えられます。
とはいえ、メインのファクターではないので、a>>bの関係が成り立ちます。
以下では、簡略化のためにドメインのスコア=リンク本数のみで決まっていると仮定します。
ステップ2.保管されている全ドメインデータの中で順位付け
Mozやahrefsのデータベ-スに保存されている全てのドメインデータの中で、それぞれのドメインが獲得しているリンクの数を算出し、順位付けを行います。
ステップ3.点数を対数目盛りで区切って近似関数を作成
ここが重要なポイントで、ドメインごとにリンクの数を算出すると
リンクが少ないドメイン→大量の存在
リンクが多いドメイン→ごく少数
という結果になるはずです。
もし、データベースの中から10000個のドメインを無作為に抜き出して、
「ドメイン個数」と「リンクの本数(スコア)」でプロットすると、以下のような分布のグラフになるはずです。
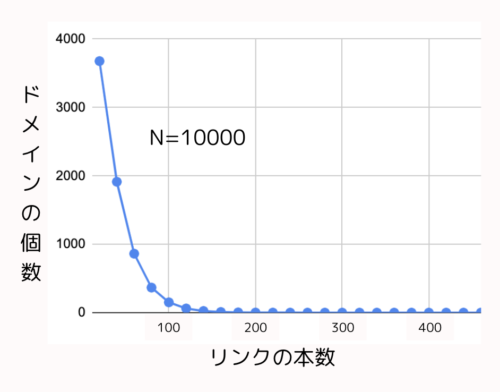
このグラフは、多くのリンクを獲得しているドメイン(高ランクのドメイン)は、ごく少数であることを表しています。
グラフの形状は指数関数となることが予想できます。
もっとも多くのリンクが当たっているドメインのランクを100、
リンクが0本のドメインのランクを0とした時に、
リンクの本数とドメインランクの関係は、以下のような形状になると予想されます。
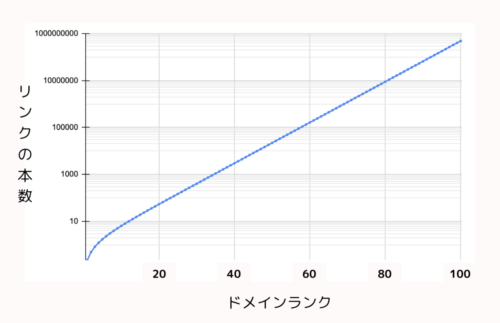
注目すべきは、リンクの本数は、対数でプロットされていることです。
ドメインの評価は、相対評価になります。
そのため上記のグラフのように、ドメインランクを上げるには、必要なドメインの本数が指数関数的に増えることが想定されます。
算出したグラフから、リンクの本数(≒ドメインスコア)とドメインランクの近侍関数を算出します。
ステップ4.近似関数に点数を代入して指標を出す
算出した近似関数にドメインスコアを代入して、ドメインランクを算出します。
ドメインのデータは、時事刻々と変化するものなので、毎回すべてのドメインをランキングするためのリソースはありません。
そのため、2ヶ月に1回くらいのスパンでデータ集計し、近似関数を作ってから、ドメインランクを算出していると思われます。