robotsメタタグ(noindex,nofollow,none)の意味や使用例

この記事では、noindex,nofollow,noneなどのrobots メタタグの意味、記載方法、使用ケースについてお伝えします。
これらのrobotsメタタグは公開前ページや個人情報が記載されたページなど、ユーザーに閲覧させたくないページに設定します。
記事内容は、以下のgoogle公式ページから抜粋しました。
robots メタタグの指定 | Google 検索セントラル | Google Developers
公開前ページなどで使えるrobotsメタタグ
noindex
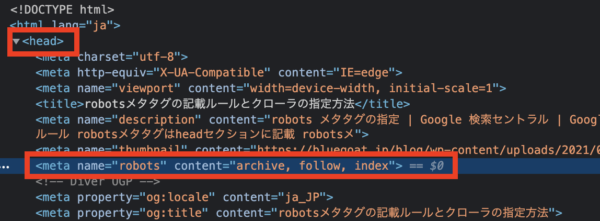
| 記述 | <meta name=”robots” content=”noindex”> | ||
|---|---|---|---|
| 意味 | インデックスさせない。 | ||
| 用途 | 重複ページや、個人情報が記載されたページなど、検索に表示させたくないページ | ||
noindexは、検索結果への表示を抑止する設定です。
クローラーによってWebページの情報の取得(クローリング)はされるのですが、検索結果には表示されません。
そのため、検索流入されることはないので、秘匿性の高いページには必ず設定する項目です。
他にも、重複コンテンツによる低評価を受けなくする目的で使われることもあります。
たとえば、ABテストを行う際に内容がほぼ同じページを作る場合がありますが、この場合は新しく作成したページにnoindexを設定します。
nofollow
| 記述 | <meta name=”robots” content=”nofollow”> | ||
|---|---|---|---|
| 意味 | ページ内のリンク(<a>タグ)を辿らない | ||
| 用途 | リンク先ページにPageRankを渡したくない時など | ||
PageRankについては現在はあまりシビアに見られていないのですが、数年前はリンクを送るとリンクジュースが減ると言われていたのですべてのリンクにnofollowを設定しているページもありました。
none
| 記述 | <meta name=”robots” content=”none”> | ||
|---|---|---|---|
| 意味 | インデックスとリンク先へのクロールの両方を拒否 | ||
| 用途 | 公開前ページなど、世間の目に触れさせたくない時。 | ||
noindex, nofollowの両方を設定する際に、noneが使えます。
と
は同じ意味になります。
初期設定と同じものは記載する必要はない
のように、初期設定(index,follow)と同じ内容の記述はあえてする必要はありません。
よくある間違い|robots.txtでDisallowを設定
インデックスさせたくないページをrobots.txtでDisallow設定すると、クローラーがインデックスさせたくないページに巡回しなくなります。
その結果、クローラは「ページにnoindex設定がされているかどうか」すらわからなくなってしまいます。
これまでインデックスされてしまっていたページをindex除外したい場合は、この状況だとずっとインデックスされ続けてしまいます。
まずはページのnoindex設定を行い、インデックス除外が確認されてからrobots.txtでDisallow設定を行いましょう。
noindexのチェック方法
メタタグが設定されているか確認する方法は、たくさんの方法があります。
一例として、海外のSEOチェックツール「Uber Suggest」を利用する方法があります。
Uber Suggestの「サイト監査」では、noindexが設定されているページがあると指摘してくれます。
他にもSEOで修正した方がいい箇所をピックアップして伝えてくれるので、とりあえず自分の運営サイトを監査してみると修正箇所が見つかるかもしれません。
「ページを公開しているのに、なかなかインデックスされない・・・」という方は試してみてください。
「サイト公開から1年以上経ってもインデックスされない」と相談を受けたこので調べてみたら、Topページにnoindexが設定されていた、というケースが実際にありました。